MapReduce介绍
条评论内容:MapReduce介绍、MapReduce处理流程
MapReduce思想
MapReduce任务过程是分为两个处理阶段:
Map阶段:Map阶段的主要作用是“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。 Map阶段的这些任务可以并行计算,彼此间没有依赖关系。
Reduce阶段:Reduce阶段的主要作用是“合”,即对map阶段的结果进行全局汇总
序列化接口
| Java基本类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
实现Writable序列化步骤
必须实现Writable接口
反序列化时,需要反射调用空参构造函数,所以必须有空参构造
重写序列化方法
1 |
|
- 重写反序列化方法
1 | public void readFields(DataInput in) throws IOException { |
反序列化的字段顺序和序列化字段的顺序必须完全一致
需要重写bean对象的toString()方法,可以自定义分隔符
如果自定义Bean对象需要放在Mapper输出KV中的K,则该对象还需实现Comparable接口,因为因 为MapReduce框中的Shuffle过程要求对key必须能排序!!
1 | public int compareTo(CustomBean o) { // 自定义排序规则 |
MapReduce原理分析
MapTask运行机制详解
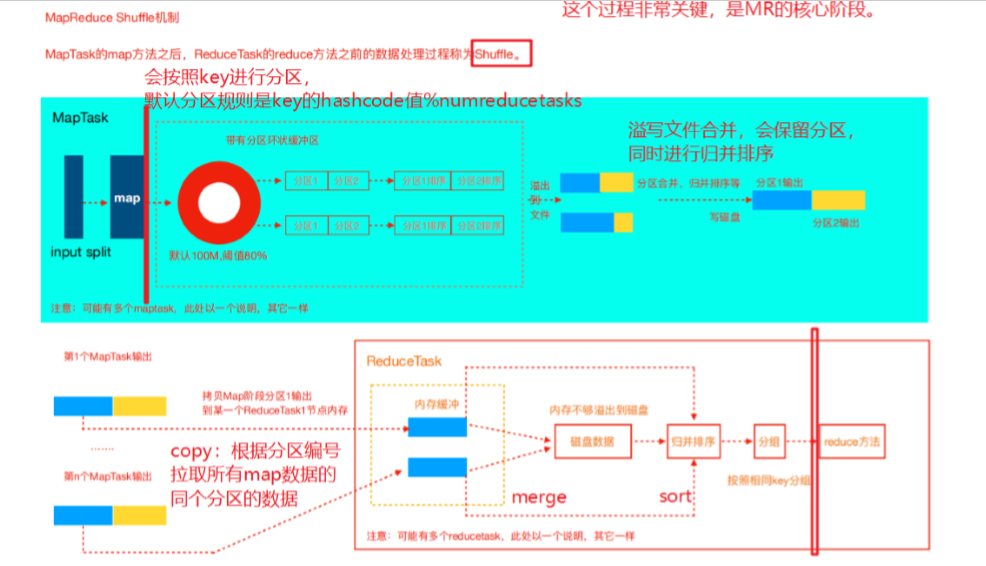
首先,读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,有多少个split就对应启动多少个MapTask。split与block的对应关 系默认是一对一。
将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以\n 作为分隔符,读取一行数据,返回<key,value>。Key表示每行首字符偏移值,value表示这一行文本内容。
读取split返回<key,value>,进入用户自己继承的Mapper类中,执行用户重写的map函数。 RecordReader读取一行这里调用一次。
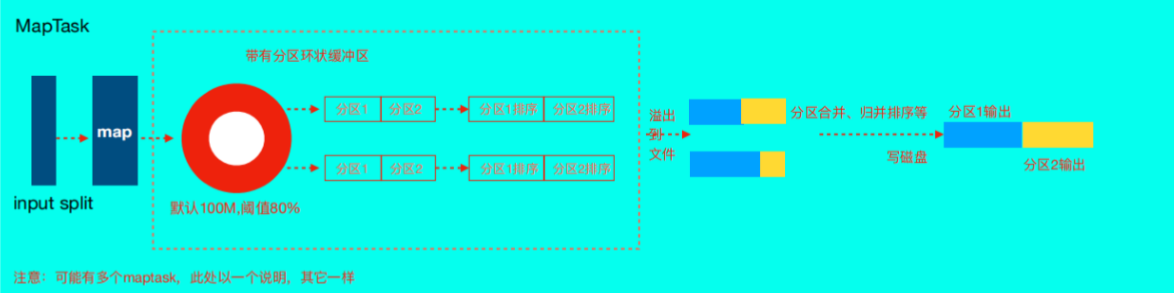
map逻辑完之后,将map的每条结果通过context.write进行collect数据收集。在collect中,会先 对其进行分区处理,默认使用HashPartitioner。
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对 输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的 取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到 job上。
接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集map结 果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之 前,key与value值都会被序列化成字节数组。
1 | 环形缓冲区其实是一个数组,数组中存放着key、value的序列化数据和key、value的元数据信息,包括partition、key的起始位置、value的起始位置以及value的 |
- 当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为
1 | 如果job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的 value加起来,减少溢写到磁盘的数据量。Combiner会优化 |
- 合并溢写文件:每次溢写会在磁盘上生成一个临时文件(写之前判断是否有combiner),如果 map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当 整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为终的文件只有一个,写入 磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量。·
MapTask的并行度
MapTask的并行度决定Map阶段的任务处理并发度,从而影响到整个Job的处理速度。
MapTask并行度决定机制
1 | 数据块:Block是HDFS物理上把数据分成一块一块。 |
切片大小默认就是128M;
MapTask并行度是不是越多越好呢?
答案不是,如果一个文件仅仅比128M大一点点也被当成一个split来对待,而不是多个split.
MR框架在并行运算的同时也会消耗更多资源,并行度越高资源消耗也越高,假设129M文件分为两个分 片,一个是128M,一个是1M; 对于1M的切片的Maptask来说,太浪费资源。
ReduceTask 工作机制
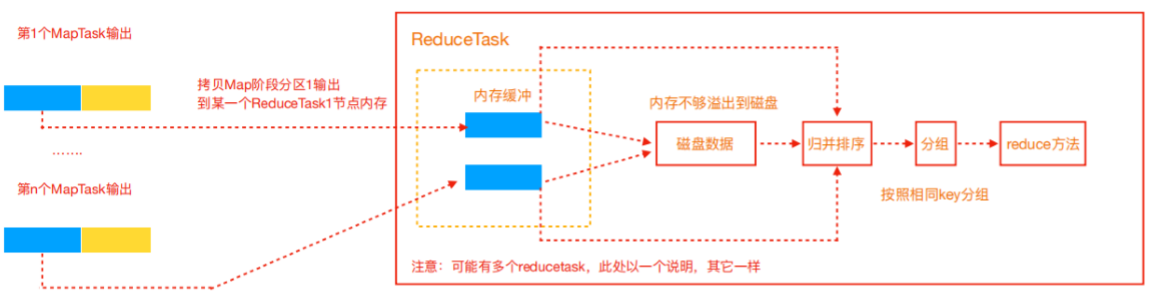
Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段。copy阶段包含一个 eventFetcher来获取已完成的map列表,由Fetcher线程去copy数据,在此过程中会启动两个merge线 程,分别为inMemoryMerger和onDiskMerger,分别将内存中的数据merge到磁盘和将磁盘中的数据 进行merge。待数据copy完成之后,copy阶段就完成了,开始进行sort阶段,sort阶段主要是执行 finalMerge操作,纯粹的sort阶段,完成之后就是reduce阶段,调用用户定义的reduce函数进行处理。
- Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求 maptask获取属于自己的文件。
- Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数 值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge 有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的 数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过 程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种 merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge 方式生成终的文件。
- 合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
- 对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个 或者多个键值对,后把这些输出的键值对写入到HDFS文件中。
ReduceTask并行度
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定 不同,ReduceTask数量的决定是可以直接手动设置:
注意事项
- ReduceTask=0,表示没有Reduce阶段,输出文件数和MapTask数量保持一致;
- ReduceTask数量不设置默认就是一个,输出文件数量为1个;
- 如果数据分布不均匀,可能在Reduce阶段产生倾斜;
Shuffle机制
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中关键的一个流程,这个流程就叫 shuffle。